

オープンセット意味抽出:Grounded-SAM、CLIP、およびDINOv2パイプライン
リンク一覧
概要と1 はじめに
-
関連研究
2.1. ビジョンと言語によるナビゲーション
2.2. セマンティックシーン理解とインスタンスセグメンテーション
2.3. 3Dシーン再構築
-
方法論
3.1. データ収集
3.2. 画像からのオープンセットセマンティック情報
3.3. オープンセット3D表現の作成
3.4. 言語誘導ナビゲーション
-
実験
4.1. 定量的評価
4.2. 定性的結果
-
結論と今後の課題、開示声明、および参考文献
3.2. 画像からのオープンセットセマンティック情報
\ 3.2.1. オープンセットセマンティックおよびインスタンスマスク検出
\ 最近リリースされたSegment Anythingモデル(SAM)[21]は、その最先端のセグメンテーション機能により、研究者や産業実務者の間で大きな人気を獲得しています。しかし、SAMは同じオブジェクトに対して過剰な数のセグメンテーションマスクを生成する傾向があります。この問題に対処するため、私たちはGrounded-SAM [32]モデルを採用しています。このプロセスは、図2に示されているように、3段階でマスクのセットを生成することを含みます。最初に、Recognizing Anythingモデル(RAM)[33]を使用してテキストラベルのセットが作成されます。その後、Grounding DINOモデル[25]を使用して、これらのラベルに対応するバウンディングボックスが作成されます。画像とバウンディングボックスはSAMに入力され、画像内で見られるオブジェクトのクラス非依存セグメンテーションマスクを生成します。以下では、RAMとGrounding-DINOからのセマンティックな洞察を取り入れることで、過剰セグメンテーションの問題を効果的に軽減するこのアプローチの詳細な説明を提供します。
\ RAMモデル[33]は、入力RGBイメージを処理して、画像内で検出されたオブジェクトのセマンティックラベリングを生成します。これは画像タグ付けのための堅牢な基盤モデルであり、様々な一般的なカテゴリを正確に識別するための顕著なゼロショット能力を示しています。このモデルの出力は、すべての入力画像を、画像内のオブジェクトカテゴリを説明するラベルのセットと関連付けます。このプロセスは、入力画像にアクセスしてRGBカラースペースに変換し、モデルの入力要件に合わせてサイズを変更し、最終的にテンソルに変換してモデルによる分析と互換性を持たせることから始まります。これに続いて、RAMモデルは画像内に存在する様々なオブジェクトや特徴を説明するラベルまたはタグを生成します。生成されたラベルを洗練するためにフィルタリングプロセスが採用され、これらのラベルから不要なクラスを削除することを含みます。具体的には、「壁」、「床」、「天井」、「オフィス」などの無関係なタグは、研究の文脈で不必要と見なされる他の事前定義されたクラスとともに破棄されます。さらに、このステージでは、RAMモデルによって最初に検出されなかった必要なクラスでラベルセットを拡張することも可能です。最後に、すべての関連情報が構造化された形式にまとめられます。具体的には、各画像はimg_dict辞書内にカタログ化され、画像のパスと生成されたラベルのセットが記録され、後続の分析のためにアクセス可能なデータリポジトリを確保します。
\ 生成されたラベルで入力画像にタグ付けした後、ワークフローはGrounding DINOモデル[25]を呼び出すことで進行します。このモデルは、テキストフレーズを画像内の特定の領域に接地させることを専門とし、バウンディングボックスでターゲットオブジェクトを効果的に描写します。このプロセスは画像内のオブジェクトを識別し空間的に局在化し、より細かい分析の基礎を築きます。バウンディングボックスを介してオブジェクトを識別し局在化した後、Segment Anything Model(SAM)[21]が採用されます。SAMモデルの主な機能は、これらのバウンディングボックス内のオブジェクトのセグメンテーションマスクを生成することです。これにより、SAMは個々のオブジェクトを分離し、画像内でオブジェクトを背景や他のオブジェクトから効果的に分離することで、より詳細でオブジェクト固有の分析を可能にします。
\ この時点で、オブジェクトのインスタンスが識別され、局在化され、分離されています。各オブジェクトは、バウンディングボックスの座標、オブジェクトの説明的な用語、ロジットで表現されるオブジェクトの存在の可能性または信頼スコア、およびセグメンテーションマスクを含む様々な詳細で識別されます。さらに、すべてのオブジェクトはCLIPとDINOv2の埋め込み特徴と関連付けられており、その詳細は次のサブセクションで詳述されています。
\ 3.2.2. セマンティック埋め込み抽出
\ 画像内でセグメント化されマスクされたオブジェクトインスタンスのセマンティックな側面の理解を向上させるために、私たちはCLIP [9]とDINOv2 [10]の2つのモデルを採用し、各オブジェクトのクロップされた画像から特徴表現を導出します。CLIPのみで訓練されたモデルは、画像の堅牢なセマンティック理解を達成しますが、それらの画像内の深度や複雑な詳細を識別することはできません。一方、DINOv2は深度認識において優れたパフォーマンスを示し、画像間のニュアンスのあるピクセルレベルの関係を識別することに優れています。自己教師あり型ビジョントランスフォーマーとして、DINOv2は注釈付きデータに依存せずに微妙な特徴の詳細を抽出でき、画像内の空間的関係と階層を識別するのに特に効果的です。例えば、CLIPモデルは赤と緑のような異なる色の2つの椅子を区別するのに苦労するかもしれませんが、DINOv2の能力はそのような区別を明確にすることを可能にします。結論として、これらのモデルはオブジェクトのセマンティックおよび視覚的特徴の両方をキャプチャし、後に3D空間での類似性比較に使用されます。
\ 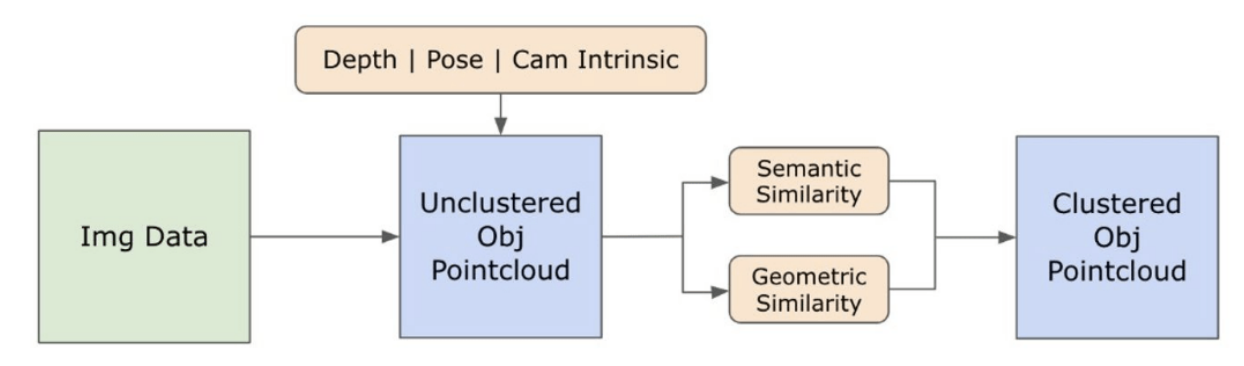
\ DINOv2モデルで画像を処理するための一連の前処理ステップが実装されています。これには、サイズ変更、中央クロップ、画像をテンソルに変換、およびバウンディングボックスで描写されたクロップ画像の正規化が含まれます。処理された画像は、RAMモデルによって識別されたラベルとともにDINOv2モデルに供給され、DINOv2埋め込み特徴を生成します。一方、CLIPモデルを扱う場合、前処理ステップはクロップされた画像をCLIPと互換性のあるテンソル形式に変換し、その後に埋め込み特徴の計算を行うことを含みます。これらの埋め込みは、オブジェクトの視覚的およびセマンティックな属性をカプセル化するため重要であり、シーン内のオブジェクトの包括的な理解に不可欠です。これらの埋め込みはL2ノルムに基づいて正規化され、特徴ベクトルを標準化された単位長に調整します。この正規化ステップにより、異なる画像間で一貫性のある公平な比較が可能になります。
\ このステージの実装フェーズでは、データ内の各画像を反復処理し、以下の手順を実行します:
\ (1) Grounding DINOモデルによって提供されるバウンディングボックス座標を使用して、画像を関心領域にクロップし、詳細な分析のためにオブジェクトを分離します。
\ (2) クロップされた画像のDINOv2とCLIPの埋め込みを生成します。
\ (3) 最後に、埋め込みは前のセクションのマスクとともに保存されます。
\ これらのステップが完了すると、各オブジェクトの詳細な特徴表現を持ち、さらなる分析とアプリケーションのためにデータセットを豊かにします。
\
:::info 著者:
(1) Laksh Nanwani、インド・ハイデラバード国際情報技術研究所;この著者は本研究に同等に貢献しました;
(2) Kumaraditya Gupta、インド・ハイデラバード国際情報技術研究所;
(3) Aditya Mathur、インド・ハイデラバード国際情報技術研究所;この著者は本研究に同等に貢献しました;
(4) Swayam Agrawal、インド・ハイデラバード国際情報技術研究所;
(5) A.H. Abdul Hafez、トルコ・ガジアンテプ・サヒンベイ・ハサン・カリヨンジュ大学;
(6) K. Madhava Krishna、インド・ハイデラバード国際情報技術研究所。
:::
:::info この論文はarxivで入手可能であり、CC by-SA 4.0 Deed(表示-継承 4.0 国際)ライセンスの下で公開されています。
:::
\
関連コンテンツ

海老原まよい、超巨大カツカレーを見事完食! あまりに柔らかいカツに「これ単体でも白米いける」と食べる手が止まらない

32,309円で購入可能! 人気タブレット『Teclast ArtPad Pro』がAmazonセール開催中(12月13日~18日)
