

技術詳細:BSGALトレーニング、Swin-Lバックボーン、動的閾値戦略
リンク一覧
概要と1 はじめに
-
関連研究
2.1. 生成的データ拡張
2.2. 能動学習とデータ分析
-
予備知識
-
提案手法
4.1. 理想的なシナリオにおける貢献度の推定
4.2. バッチ処理ストリーミング生成能動学習
-
実験と5.1. オフライン設定
5.2. オンライン設定
-
結論、より広範な影響、および参考文献
\
A. 実装の詳細
B. さらなるアブレーション実験
C. 考察
D. 可視化
A. 実装の詳細
A.1. データセット
我々は実験のためのデータセットとしてLVIS(Gupta et al., 2019)を選択しました。LVISは大規模なインスタンスセグメンテーションデータセットであり、約160,000枚の画像と1203の実世界カテゴリにわたる200万以上の高品質なインスタンスセグメンテーションアノテーションを含んでいます。このデータセットは、画像間での出現頻度に基づいて、希少、一般、頻繁の3つのカテゴリにさらに分けられています。「希少」とマークされたインスタンスは1〜10枚の画像に出現し、「一般」のインスタンスは11〜100枚の画像に出現し、「頻繁」なインスタンスは100枚以上の画像に出現します。データセット全体は長いテール分布を示し、実世界のデータ分布に非常に似ており、少数ショットセグメンテーション(Liu et al., 2023)やオープンワールドセグメンテーション(Wang et al., 2022; Zhu et al., 2023)など、複数の設定で広く適用されています。したがって、LVISを選択することで、実世界のシナリオにおけるモデルのパフォーマンスをより良く反映できると考えています。我々は公式のLVISデータセット分割を使用し、トレーニングセットに約100,000枚の画像、検証セットに20,000枚の画像を含んでいます。
A.2. データ生成
我々のデータ生成とアノテーションプロセスはZhao et al.(2023)と一致しており、ここで簡単に紹介します。まず、生成モデルとしてStableDiffusion V1.5(Rombach et al., 2022a)(SD)を使用します。LVIS(Gupta et al., 2019)の1203カテゴリについて、カテゴリごとに1000枚の画像を生成し、画像解像度は512×512です。生成のためのプロンプトテンプレートは「a photo of a single {CATEGORY NAME}」です。生成された生の画像にアノテーションを付けるために、U2Net(Qin et al., 2020)、SelfReformer(Yun and Lin, 2022)、UFO(Su et al., 2023)、CLIPseg(Luddecke and Ecker, 2022)をそれぞれ使用し、最も高いCLIPスコアを持つマスクを最終的なアノテーションとして選択します。データ品質を確保するために、CLIPスコアが0.21未満の画像は低品質画像としてフィルタリングされます。トレーニング中、データ拡張のためにZhao et al.(2023)が提供するインスタンスペースト戦略も採用しています。各インスタンスについて、トレーニングセットにおけるそのカテゴリの分布に合わせてランダムにサイズを変更します。1枚の画像あたりの最大ペースト数は20に設定されています。
\ さらに、生成されたデータの多様性を拡大し、研究をより普遍的にするために、DeepFloyd-IF(Shonenkov et al., 2023)(IF)やPerfusion(Tewel et al., 2023)(PER)など、他の生成モデルも使用し、モデルごとにカテゴリあたり500枚の画像を生成しました。IFについては、著者が提供する事前学習済みモデルを使用し、生成された画像はステージIIの出力で、解像度は256×256です。PERについては、ベースモデルとしてStableDiffusion V1.5を使用しています。各カテゴリについて、トレーニングセットから切り取った画像を使用してモデルを微調整し、400回の微調整ステップを行いました。微調整されたモデルを使用して画像を生成しています。
\ 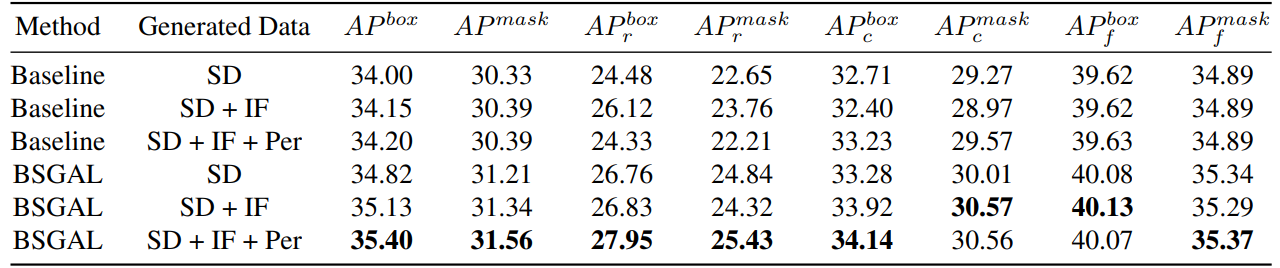
\ また、異なる生成データを使用することがモデルのパフォーマンスに与える影響も調査しました(表7参照)。元のStableDiffusion V1.5をベースにして、他の生成モデルを使用することでパフォーマンスの向上が見られますが、この改善は顕著ではありません。特に、特定の頻度カテゴリについては、IFは希少カテゴリに対してより顕著な改善を示し、PERは一般カテゴリに対してより顕著な改善を示すことがわかりました。これはおそらく、IFデータがより多様である一方、PERデータはトレーニングセットの分布とより一致しているためでしょう。全体的なパフォーマンスがある程度向上したことを考慮して、最終的に後続の実験ではSD + IF + PERの生成データを採用しました。
A.3. モデルトレーニング
Zhao et al.(2023)に従い、セグメンテーションモデルとしてCenterNet2(Zhou et al., 2021)を使用し、バックボーンとしてResNet-50(He et al., 2016)またはSwin-L(Liu et al., 2022)を使用しています。ResNet-50については、最大トレーニング反復回数は90,000に設定され、モデルは最初にImageNet-22kで事前学習された後、LVIS(Gupta et al., 2019)で微調整された重みで初期化されています。これはZhao
\ 
\ et al.(2023)が行ったのと同様です。そして、トレーニング中はバッチサイズ16で4台のNvidia 4090 GPUを使用しています。Swin-Lについては、最大トレーニング反復回数は180,000に設定され、モデルはImageNet-22kで事前学習された重みで初期化されています。これは、初期の実験でこの初期化がLVISで訓練された重みと比較してわずかな改善をもたらすことが示されたためです。そして、トレーニングにはバッチサイズ16で4台のNvidia A100 GPUを使用しています。さらに、Swin-Lのパラメータ数が多いため、勾配を保存するための追加メモリが大きくなるので、実際にはアルゴリズム2のアルゴリズムを使用しています。
\ その他の未指定のパラメータもX-Paste(Zhao et al., 2023)と同じ設定に従っています。例えば、初期学習率1e-4のAdamW(Loshchilov and Hutter, 2017)オプティマイザなどです。
A.4. データ量
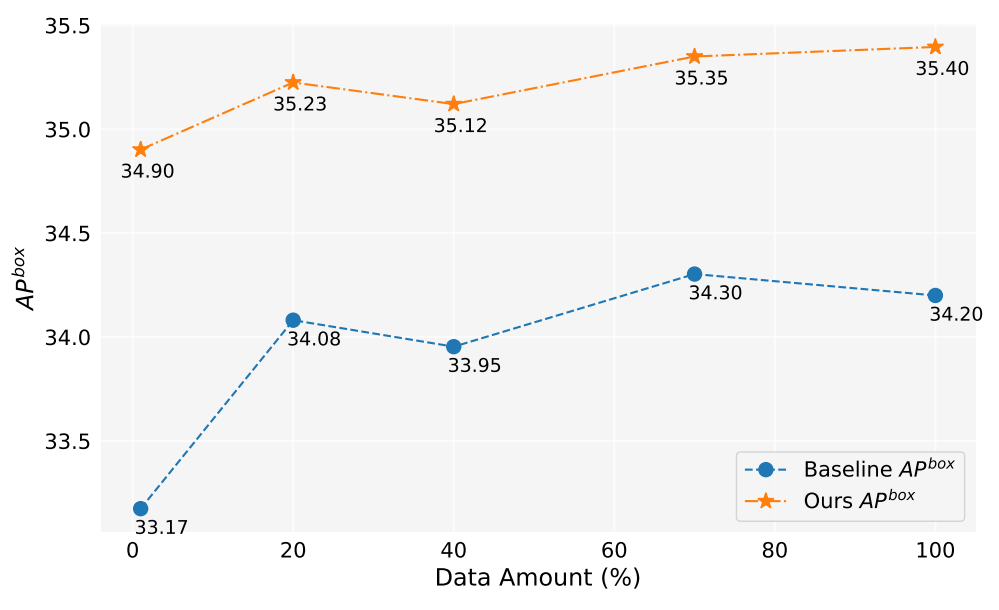
この研究では、200万枚以上の画像を生成しました。図5は、異なる量の生成データ(1%、10%、40%、70%、100%)を使用した場合のモデルのパフォーマンスを示しています。全体として、生成データの量が増えるにつれて、モデルのパフォーマンスも向上しますが、多少の変動もあります。我々の手法は常にベースラインよりも優れており、これは我々の手法の有効性と堅牢性を証明しています。
A.5. 貢献度推定
\ したがって、我々は本質的にコサイン類似度を計算しています。次に、表8に示すように実験的比較を行いました。
\ 
\ 
\ 勾配を正規化すると、我々の手法にある程度の改善がもたらされることがわかります。さらに、2つの異なる閾値を維持する必要があるため、受け入れ率の一貫性を確保することが難しくなります。そこで、動的閾値戦略を採用し、受け入れ率を事前に設定し、前回の反復の貢献度を保存するためのキューを維持し、そのキューに従って閾値を動的に調整することで、受け入れ率が事前に設定された受け入れ率に留まるようにしています。
A.6. おもちゃの実験
CIFAR-10で実装された具体的な実験設定は以下の通りです:ベースラインモデルとして単純なResNet18を採用し、200エポックにわたってトレーニングを行いました。元のトレーニングセットでトレーニングした後の精度は93.02%です。学習率は0.1に設定され、SGDオプティマイザを使用しています。モメンタムは0.9で、重み減衰は5e-4です。コサインアニーリング学習率スケジューラを使用しています。構築されたノイズ画像は図6に示されています。ノイズレベルが上昇するにつれて画像品質の低下が観察されます。特に、ノイズレベルが200に達すると、画像の識別が著しく困難になります。表1では、Split1をRとして使用し、Gは「Split2 + Noise40」、「Split3 + Noise100」、「Split4 + Noise200」で構成されています。
A.7. 一度だけ順伝播する簡略化
\
:::info 著者:
(1) 朱牧之、浙江大学(中国)からの同等の貢献;
(2) 范成祥、浙江大学(中国)からの同等の貢献;
(3) 陳浩、浙江大学(中国)([email protected]);
(4) 劉陽、浙江大学(中国);
(5) 毛偉安、浙江大学(中国)およびアデレード大学(オーストラリア);
(6) 徐暁剛、浙江大学(中国);
(7) 沈春華、浙江大学(中国)([email protected])。
:::
:::info この論文は arxivで入手可能 であり、CC BY-NC-ND 4.0 Deed(Attribution-Noncommercial-Noderivs 4.0 International)ライセンスの下で公開されています。
:::
\
関連コンテンツ

Stellar、データ駆動型スマートコントラクトを強化するためにSpace and Timeと統合

対照的な2つの世界観! ム月、初の写真集2作品をBOOTHで通販開始
