

Detección de anomalías basada en Transformer utilizando incrustaciones de secuencias de registros
Tabla de enlaces
Abstracto
1 Introducción
2 Antecedentes y Trabajos Relacionados
2.1 Diferentes Formulaciones de la Tarea de Detección de Anomalías Basada en Logs
2.2 Supervisado vs. No Supervisado
2.3 Información dentro de los Datos de Log
2.4 Agrupación de Ventana Fija
2.5 Trabajos Relacionados
3 Un Enfoque Configurable de Detección de Anomalías Basado en Transformer
3.1 Formulación del Problema
3.2 Análisis de Logs y Embedding de Logs
3.3 Codificación Posicional y Temporal
3.4 Estructura del Modelo
3.5 Clasificación Binaria Supervisada
4 Configuración Experimental
4.1 Conjuntos de Datos
4.2 Métricas de Evaluación
4.3 Generación de Secuencias de Logs de Longitudes Variables
4.4 Detalles de Implementación y Entorno Experimental
5 Resultados Experimentales
5.1 RQ1: ¿Cómo se comporta nuestro modelo de detección de anomalías propuesto en comparación con las líneas base?
5.2 RQ2: ¿Cuánto afecta la información secuencial y temporal dentro de las secuencias de logs a la detección de anomalías?
5.3 RQ3: ¿Cuánto contribuyen individualmente los diferentes tipos de información a la detección de anomalías?
6 Discusión
7 Amenazas a la validez
8 Conclusiones y Referencias
\
3 Un Enfoque Configurable de Detección de Anomalías Basado en Transformer
En este estudio, presentamos un nuevo método basado en transformer para la detección de anomalías. El modelo toma secuencias de logs como entradas para detectar anomalías. El modelo emplea un modelo BERT preentrenado para incorporar plantillas de logs, permitiendo la representación de información semántica dentro de los mensajes de logs. Estos embeddings, combinados con codificación posicional o temporal, se introducen posteriormente en el modelo transformer. La información combinada se utiliza en la posterior generación de representaciones a nivel de secuencia de logs, facilitando el proceso de detección de anomalías. Diseñamos nuestro modelo para que sea flexible: Las características de entrada son configurables para que podamos usar o realizar experimentos con diferentes combinaciones de características de los datos de logs. Además, el modelo está diseñado y entrenado para manejar secuencias de logs de entrada de longitudes variables. En esta sección, presentamos nuestra formulación del problema y el diseño detallado de nuestro método.
\ 3.1 Formulación del Problema
Seguimos los trabajos anteriores [1] para formular la tarea como una tarea de clasificación binaria, en la que entrenamos nuestro modelo propuesto para clasificar secuencias de logs en anomalías y normales de manera supervisada. Para las muestras utilizadas en el entrenamiento y evaluación del modelo, utilizamos un enfoque de agrupación flexible para generar secuencias de logs de longitudes variables. Los detalles se presentan en la Sección 4
\ 3.2 Análisis de Logs y Embedding de Logs
En nuestro trabajo, transformamos eventos de logs en vectores numéricos mediante la codificación de plantillas de logs con un modelo de lenguaje preentrenado. Para obtener las plantillas de logs, adoptamos el analizador Drain [24], que es ampliamente utilizado y tiene un buen rendimiento de análisis en la mayoría de los conjuntos de datos públicos [4]. Utilizamos un modelo sentence-bert preentrenado [25] (es decir, all-MiniLML6-v2 [26]) para incorporar las plantillas de logs generadas por el proceso de análisis de logs. El modelo preentrenado se entrena con un objetivo de aprendizaje contrastivo y logra un rendimiento de vanguardia en varias tareas de NLP. Utilizamos este modelo preentrenado para crear una representación que capture información semántica de los mensajes de logs e ilustre la similitud entre plantillas de logs para el modelo de detección de anomalías posterior. La dimensión de salida del modelo es 384.
\ 3.3 Codificación Posicional y Temporal
El modelo transformer original [27] adopta una codificación posicional para permitir que el modelo utilice el orden de la secuencia de entrada. Como el modelo no contiene recurrencia ni convolución, los modelos serán agnósticos a la secuencia de logs sin la codificación posicional. Aunque algunos estudios sugieren que los modelos transformer sin codificación posicional explícita siguen siendo competitivos con los modelos estándar cuando se trata de datos secuenciales [28, 29], es importante tener en cuenta que cualquier permutación de la secuencia de entrada producirá el mismo estado interno del modelo. Como la información secuencial o temporal puede ser un indicador importante de anomalías dentro de las secuencias de logs, trabajos anteriores basados en modelos transformer utilizan la codificación posicional estándar para inyectar el orden de eventos de logs o plantillas en la secuencia [11, 12, 21], con el objetivo de detectar anomalías asociadas con un orden de ejecución incorrecto. Sin embargo, notamos que en una implementación de replicación comúnmente utilizada de un método basado en transformer [5], la codificación posicional fue, de hecho, omitida. Hasta donde sabemos, ningún trabajo existente ha codificado la información temporal basada en las marcas de tiempo de los logs para su método de detección de anomalías. La efectividad de utilizar información secuencial o temporal en la tarea de detección de anomalías no está clara.
\ En nuestro método propuesto, intentamos incorporar codificación secuencial y temporal en el modelo transformer y explorar la importancia de la información secuencial y temporal para la detección de anomalías. Específicamente, nuestro método propuesto tiene diferentes variantes que utilizan las siguientes técnicas de codificación secuencial o temporal. La codificación se agrega luego a la representación de logs, que sirve como entrada a la estructura transformer.
\ 
3.3.1 Codificación de Tiempo Transcurrido Relativo (RTEE)
Proponemos este método de codificación temporal, RTEE, que simplemente sustituye el índice de posición en la codificación posicional con el tiempo de cada evento de log. Primero calculamos el tiempo transcurrido según las marcas de tiempo de los eventos de logs en la secuencia de logs. En lugar de usar el índice de secuencia de eventos de logs como la posición para las ecuaciones sinusoidales y cosinusoidales, usamos el tiempo transcurrido relativo al primer evento de log en la secuencia de logs para sustituir el índice de posición. La Tabla 1 muestra un ejemplo de intervalos de tiempo en una secuencia de logs. En el ejemplo, tenemos una secuencia de logs que contiene 7 eventos con un lapso de tiempo de 7 segundos. El tiempo transcurrido desde el primer evento hasta cada evento en la secuencia se utiliza para calcular la codificación de tiempo para los eventos correspondientes. Similar a la codificación posicional, la codificación se calcula con las ecuaciones 1 mencionadas anteriormente, y la codificación no se actualizará durante el proceso de entrenamiento.
\ 
3.4 Estructura del Modelo
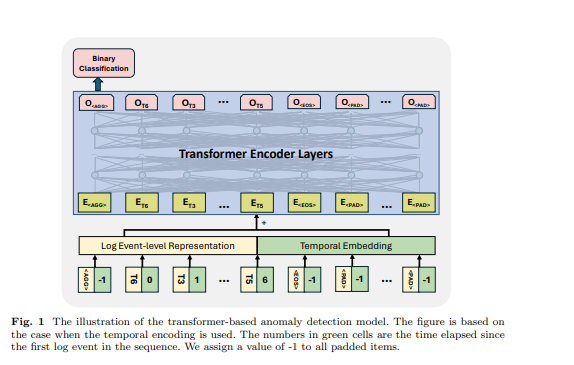
El transformer es una arquitectura de red neuronal que se basa en el mecanismo de autoatención para capturar la relación entre elementos de entrada en una secuencia. Los modelos y marcos basados en transformer han sido utilizados en la tarea de detección de anomalías por muchos trabajos anteriores [6, 11, 12, 21]. Inspirados por los trabajos anteriores, utilizamos un modelo basado en codificador transformer para la detección de anomalías. Diseñamos nuestro enfoque para aceptar secuencias de logs de longitudes variables y generar representaciones a nivel de secuencia. Para lograr esto, hemos empleado algunos tokens específicos en la secuencia de logs de entrada para que el modelo genere representación de secuencia e identifique los tokens rellenados y el final de la secuencia de logs, inspirándonos en el diseño del modelo BERT [31]. En la secuencia de logs de entrada, utilizamos los siguientes tokens: se coloca al inicio de cada secuencia para permitir que el modelo genere información agregada para toda la secuencia, se agrega al final de la secuencia para indicar su finalización, se utiliza para marcar los tokens enmascarados bajo el paradigma de entrenamiento autosupervisado, y se utiliza para tokens rellenados. Los embeddings para estos tokens especiales se generan aleatoriamente según la dimensión de la representación de logs utilizada. Un ejemplo se muestra en la Figura 1, el tiempo transcurrido para , y se establece en -1. La representación a nivel de evento de log y el embedding posicional o temporal se suman como la característica de entrada de la estructura transformer.
\ 3.5 Clasificación Binaria Supervisada Bajo este objetivo de entrenamiento, utilizamos la salida del primer token del modelo transformer mientras ignoramos las salidas de los otros tokens. Esta salida del primer token está diseñada para agregar la información de toda la secuencia de logs de entrada, similar al token del modelo BERT, que proporciona una representación agregada de la secuencia de tokens. Por lo tanto, consideramos la salida de este token como una representación a nivel de secuencia. Entrenamos el modelo con un objetivo de clasificación binaria (es decir, Pérdida de Entropía Cruzada Binaria) con esta representación.
\ 
:::info Autores:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC by 4.0 Deed (Atribución 4.0 Internacional).
:::
\
También te puede interesar

Villarruel apuntó contra Adorni por el viaje de su esposa en el avión presidencial a Nueva York

Qué selección de fútbol podría reemplazar a Irán en el Mundial 2026
